Attention is all you need
Published: 4/7/2025
背景
transformer提出以前,序列建模通常使用RNN,LSTM,GRU(后两个都基于RNN)等模型。考虑一组序列输入,目标为一组序列输出,RNN通过当前输入与前一步隐藏状态 来预测当前位置输出,其计算通常为:
其中分别为输入到隐藏层,隐藏层到隐藏层,隐藏层到输出层的权重矩阵,为偏置项, 隐藏层的加入使得RNN能够捕捉上下文关系。
具体而言,通过参数矩阵来将 与 线性变换到某个向量空间, 其中的向量也就是特征,用于表示某一属性的模式,被模型理解使用;引入激活函数则是为了引入非线性变换来捕捉更复杂模式)。
虽然RNN能够捕捉上下文关系,但是 是一个定长向量,限制了RNN只能捕捉有限长度,在长序列输入训练时,会出现梯度消失等问题, 推理时也会出现丢失远距离上下文的问题。LSTM与gated RNN(LSTM简化)引入门控单元来选择保留长距离上下文信息,解决了RNN中的问题。
以RNN为基础的模型问题在于其递归结构导致无法并行化计算,并且远距离关系的捕捉仍比较困难。
注意力最早提出于2014年1,《Attention is all you need》2则系统地提出了注意力机制与 完全基于注意力机制的Transformer架构,并取得了极好的成果。
Transformer
Attention
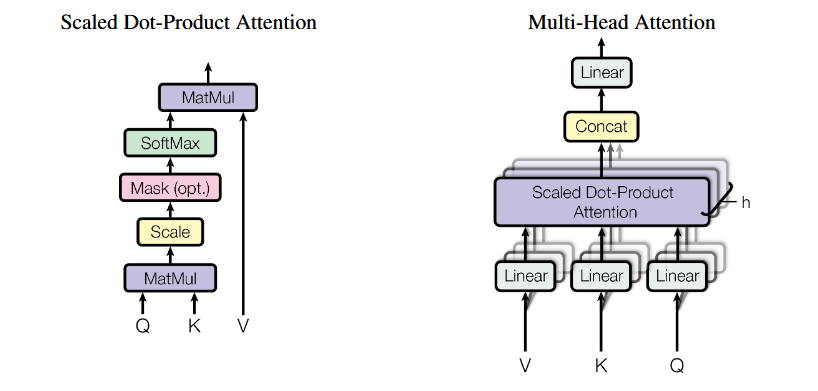
注意力机制的输入是一个维的向量,输出则是一个w维的向量,在计算过程中,通过将通过可训练的投影矩阵 ,,分别映射到对应线性空间,,,并利用投影得到的向量与之前位置的组成的矩阵相乘得到 计算注意力分数(表示当前位置与之前的哪些位置更相关),然后使用softmax归一化并于之前位置的相乘得到输出向量,计算公式如下:
多头注意力则使用多个注意力头(,,矩阵, )分别计算结果,最后通过一个可训练的权重矩阵拼接得到最终输出向量。 这么做的意义在于,每个注意力都可以捕捉到一些特征模式,最后通过权重矩阵来进行加权,使得模型的表达能力更强,计算公式如下:
论文中也给出了计算图示:
Encoder and Decoder
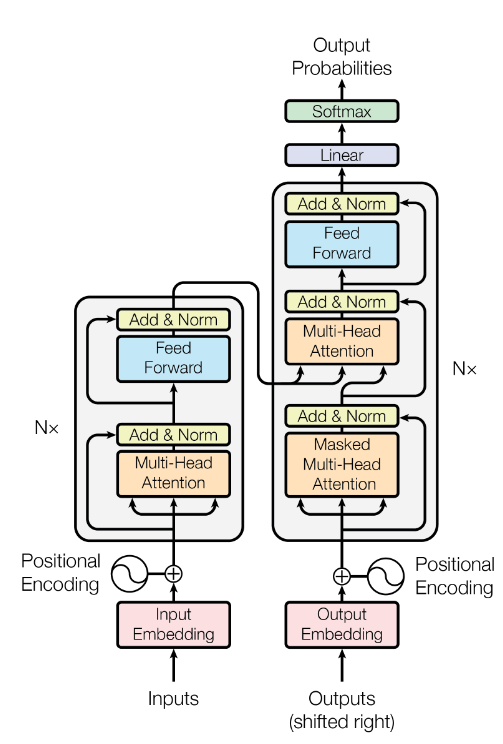
transformer架构如上图所示,主要由Decoder与Encoder组成。其中,Encoder中的每层主要有多头注意力与FNN,这两个每个都有一个残差网络 用于防止梯度消失,优化训练过程。
残差网络ResNet 主要通过 来在梯度传播时引入梯度1的路径,避免梯度消失问题;归一化Norm则可以将输出分布标准化,优化训练过程; FFN则是增强模型表达能力。
Decoder和Encoder相比,多了Masked Multi-head Attention层,该层主要在计算注意力分数时使用因果掩码Casual Mask遮盖了后续位置的值,主要用于防止模型在训练时看到未来的信息。
Encoder主要负责将输入序列编码为上下文向量,Decoder则主要负责将上下文向量解码为输出序列(通过softmax归一化给出词汇表中每个token的概率分布)。 目前大多数自回归模型(比如GPT)都只使用Decoder(Decoder-only),Encoder-decoder主要用于序列到序列的任务(如翻译)。
enmedding and position encoding
从transformer的架构图可以看到,输入序列还需要经过embedding与position encoding 两个步骤。embedding主要负责将输入文本转化为模型可使用的向量表示,使用分词器tokenizer将输入序列中的每个子词引导到词汇表中对应的索引,然后通过查词汇表得到其对应的向量表示。position encoding则主要负责对embedding 后的向量进行位置编码,让模型能够捕捉每个token的位置信息。这里2使用了固定的正余弦函数来对每个位置进行编码,计算公式如下:
其中 为位置(token),为维度索引(向量中的位置),为模型的维度。这样会发现这是一个周期函数,一些基于该position encoding的文本补全模型会出现循环输出的情况。
Roformer3中提出了RoPE(Rotary Position Embedding)旋转位置编码,通过将嵌入向量的每一对维度与2X2旋转矩阵相乘来进行encoding,具体计算方式如下:
其中,为维度索引,为token位置。利用该公式推导注意力分数的计算,会发现 注意力分数依赖于与的相对位置(两个旋转矩阵),天然就包括了相对位置关系,模型能够更好地学习顺序依赖,而绝对位置编码(比如之前的正余弦) 则需要模型额外地学习输入中的相对位置关系。
KV cache
注意力分数计算时,会使用当前token的Query向量与之前token的Key向量相乘得到与之前位置的注意力分数,最后与之前位置的Value向量相乘得到输出。 由于Key和Value向量一次计算即可得到,所以可以不断地缓存已计算过的Key和Value向量来减少计算,但这也对模型推理的存储提高了要求(与输入序列 长度呈正比)。KV cache大小的计算公式为:
其中:
- : 表示 Key 和 Value
- : 批量大小
- : 当前序列长度
- : 注意力头数
- : 每个注意力头的维度
- : 层数
- : 数据类型的大小
inference
自回归模型推理主要分为prefill与decode两个阶段,prefill阶段主要负责处理所有的输入序列prompt,并行计算每个位置的Key和value,主要是计算密集型; decode阶段则利用prefill得到的KV cache,使用bos作为初始输入来串行计算后续位置,并将Key与Value向量追加到KV cache中,计算相对prefill阶段较弱, 主要集中于KV cache的I/O读取,I/O密集型。
相关工作
Footnotes
-
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. CoRR, abs/1409.0473, 2014. ↩
-
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and others. Attention is all you need. In Advances in Neural Information Processing Systems 30 (NeurIPS 2017), 2017. ↩ ↩2
-
Su J, Ahmed M, Lu Y, et al. Roformer: Enhanced transformer with rotary position embedding[J]. Neurocomputing, 2024, 568: 127063. ↩